NPCs That Remember You: A Living World on a Single GPU
For a long time the dream of game AI has been simple to describe and brutal to ship: characters that remember what you told them, change their mind about you over time, and gossip about you behind your back. Scripted dialog trees give you the illusion of it. Big-budget MMOs fake it with conditional flags. Indie LLM experiments usually stop at "the goblin can hold one conversation, sort of."
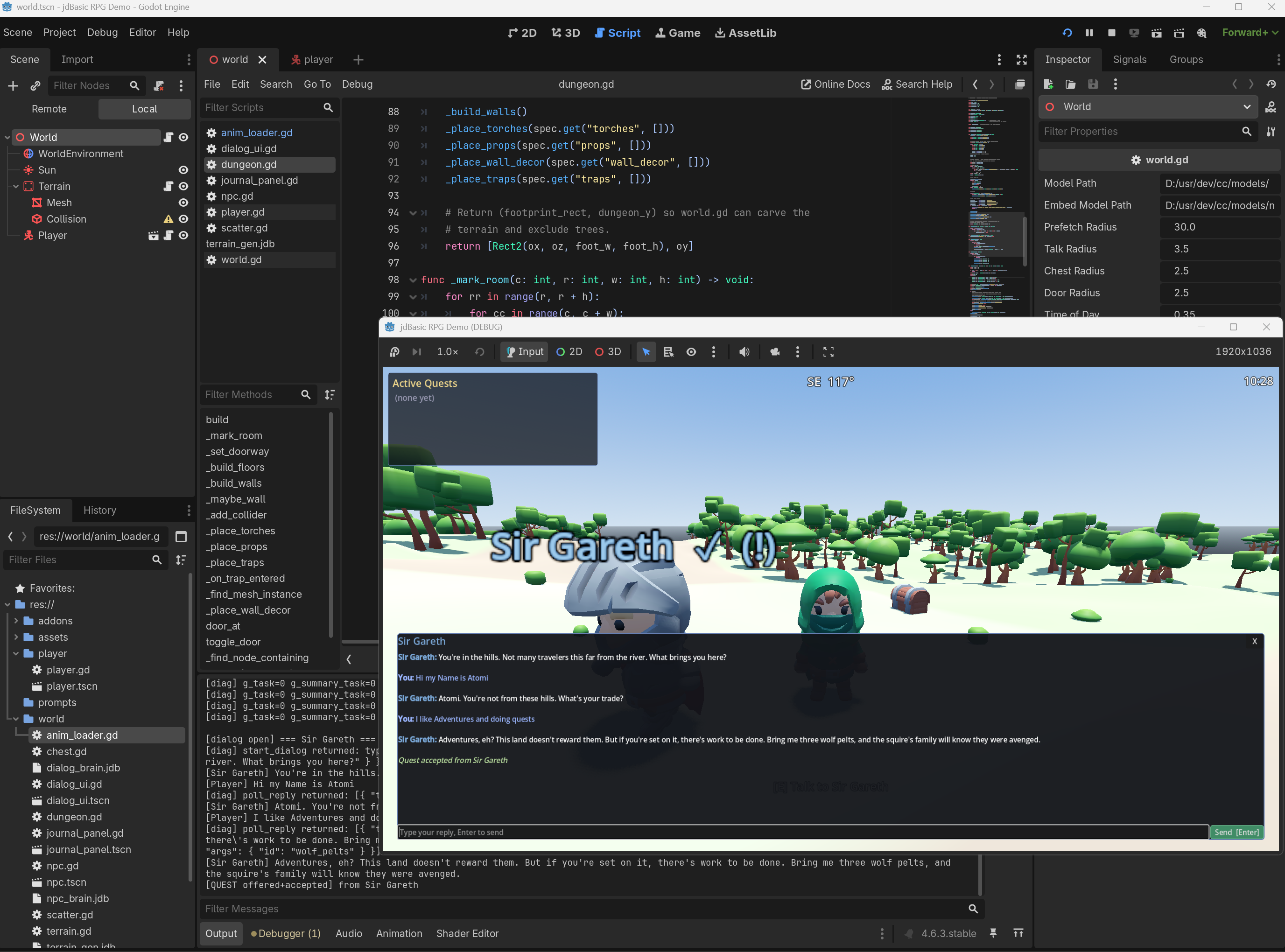
This post is about the version that runs entirely on my desk, on a single RTX 4070 Ti SUPER, in a Godot 4.6 sandbox driven by jdBasic with an embedded Qwen3-14B. Four NPCs, three story acts, six lore documents, and roughly 30 minutes of play loop, all generated locally with no cloud calls.
1. The setup, in one paragraph
Godot 4.6 handles the world (terrain, NPCs, dungeon, day/night cycle, dialog UI). jdBasic, embedded as a GDExtension, owns the brain: NPC state, quest tracking, world state, story progression, RAG retrieval, and the LLM dispatcher. Qwen3-14B-Q4 lives in VRAM via llama.cpp. A nomic-embed-text model indexes six markdown lore files for RAG. The whole stack boots in under 10 seconds and pushes the first NPC greeting before you can walk three meters.
2. Layer 5 - World State + Tick Engine
The world has a day counter, six binary flags (saw_tracks, scouted_north, keep_investigated, ...), three counters (wolves_killed, ...) and an event log. As the in-game clock crosses midnight, advance_world_day() bumps the counter. Flags drive a derived "mood" string ("peaceful", "uneasy", "tense", "foreboding", "dire") which feeds back into every NPC prompt as context.
Everything lives in world_state.json. No code change is needed to add a new flag or counter. The brain reads it once at boot and treats it as the canonical store for the rest of the session.
3. Layer 6 - Storyline Arc System
Three acts in story.json. Each act has triggers (flag combinations that activate it), completion conditions (flag combinations that close it out) and a free-form narrative string that gets injected into every active NPC prompt. The acts are:
- Act 1: Arrival in the Hills. Active by default. Quests are small, life is ordinary.
- Act 2: Tracks Lead North. Activates when both
saw_tracksandscouted_northare true. NPCs start mentioning the old keep instead of their personal quests. - Act 3: Into the Keep. Activates when the player investigated the keep. Wolves and herbs are now preparation, not side-quests.
Whenever a flag flips, check_story_progression() re-evaluates every act and emits an event ("a new chapter begins"). The dialog UI drains those events on the next reply tick and renders them as gold text inline with the conversation.
4. Layer 7 - NPC Affinity
Every NPC starts at affinity 0, on a -100 to +100 scale. Two sources push it up or down:
- Deterministic keyword detection in the brain. "Danke" or "thanks" or "ich helfe" adds +5. "Pappnase" or "shut up" subtracts 5. Handing over an expected item is worth +10. The keyword tables live in
dialog_rules.json. - LLM-emitted
shift_affinitytool calls. When Qwen3 picks up on something subtler ("you've saved my squire's name from oblivion") it can emit its own delta, capped at +/-10 per turn.
The Journal panel has a Reputation tab with a progress bar per NPC, coloured red through grey to green. The current band ("hates", "wary", "neutral", "friendly", "trusts") is fed back into the NPC's system prompt as a phrase like "Tylen fully trusts you and will speak freely about anything." The character's behaviour changes as the score climbs.
5. Layer 8 - Rumour Propagation
This is the layer that surprised me most when it started working. When you tell Tylen "I saw strange tracks at the river bend," the brain does three things at once:
- Sets the world flag
saw_tracks = true. - Re-evaluates the story arc system. Act 1 might complete, Act 2 might activate.
- Pushes a rumour onto
world_state.rumors: "Tylen found strange tracks at the river bend."
The next time you approach Gareth, his system prompt contains a Local rumours you have heard section listing that rumour, source-attributed. The very first reply will be something like: "Tracks at the river bend? Aye, I've heard the rumors. They're not wolf tracks, not quite." You didn't tell Gareth. Tylen didn't tell Gareth either. The world told Gareth.
Rumours rotate out after the buffer hits 6 entries. The source of every rumour is hidden from that NPC's prompt so Tylen never reads quotes attributed to himself.
6. Why deterministic + LLM-emitted is the right pattern
Early in the build I tried to push everything through the LLM. Tell the model "if the player describes tracks, please emit set_flag." It worked maybe four times out of ten. Qwen3 would either ignore the directive, invent a flag name that didn't exist, or set the flag to false for reasons known only to itself.
The fix was to read the player's text in jdBasic first, run a keyword + context-keyword match against the trigger table in world_state.json, and queue the corresponding tool actions as a "pending" list before the LLM even sees the turn. When the model responds, the brain prepends its own deterministic actions to whatever the LLM emitted. The UI dispatcher doesn't know or care which side originated which action.
This combo means the game state is reliable (the keyword matcher does not hallucinate), while the LLM still gets agency for the subtle cases the matcher misses. About 70% of meaningful state changes come from the deterministic side, 30% from the model, with very little overlap.
7. The Qwen3 + chat-template trap
Switching from Qwen2.5-7B to Qwen3-14B for the dialog model broke the world in an interesting way. The first NPC greeting came back as an endless wall of <|user|><|end|><|user|><|end|>... tokens.
The cause: my embedded llama.cpp wrapper had a hardcoded Phi-3-style chat template (<|system|>...<|end|>). Qwen2.5 was tolerant of it. Qwen3 was not - it treats unknown special tokens as content and keeps regenerating them until n_predict runs out.
The fix in src/llm.cpp is to ask the loaded model for its embedded chat template via llama_model_chat_template() and feed the conversation through llama_chat_apply_template(), falling back to the legacy hardcoded path only when the model has no template. After that, ChatML-style models (Qwen, Hermes) and Mistral-style models both work without code changes.
Bonus footgun: Qwen3 has a built-in thinking mode that emits <think>...</think> blocks before the actual answer. The docs say to suppress it with /no_think in the user message, not the system prompt. Belt-and-suspenders: the response parser strips anything up to and including </think> before JSON-parsing, so even if the directive is ignored, the JSON tool calls land cleanly.
8. Everything is JSON, the code is just logic
A self-imposed rule from the start: no user-visible string lives in code. Personas, quest descriptions, system prompts, mood descriptors, affinity labels, rumour templates, story narratives, even the keyword tables that drive flag detection - all of it is in JSON or markdown files. The jdBasic side holds only the logic that consumes them.
This pays off the moment you want to translate the game, add a new act, or hand the world over to someone else to play with. Adding a fifth NPC is roughly: append a row to npcs.json, give them a spawn position, optionally write a new lore markdown file with their personal history. No code change needed. The RAG layer auto-indexes the new lore, the prefetch loop spawns their greeting, and the rumour system starts attributing things to them.
9. Performance on a single 4070 Ti SUPER
Qwen3-14B-Q4_K_M weighs 9 GB and fits comfortably in 16 GB VRAM at 8k context. Greeting prefetch takes around 1.5 seconds per NPC at 50 tok/s. Live replies during conversation come back in 2-4 seconds depending on prompt size (RAG adds about 500 tokens, story + affinity + rumours another 200). Summary compaction runs on the same model in a separate async task slot, never blocking dialog.
The full system prompt for a single turn at peak state runs around 6,000 characters. Qwen3 handles that cleanly. Earlier 7B models needed aggressive context trimming; 14B at this size is the sweet spot.
10. What I learned
Three things that surprised me:
- Source-attributed rumours feel alive in a way scripted "NPCs share knowledge" doesn't. When Gareth says "Tylen spoke of strange marks" without the player ever mentioning Tylen, the world stops being a stage and becomes a place.
- The hybrid deterministic + LLM approach scales better than pure-LLM tool calling. The 30% of actions the LLM does emit are organic and surprising. The 70% the keyword matcher catches are reliable and never break the game. Neither side has to be perfect.
- jdBasic as the glue language was the right call. Live-reload during gameplay (edit
dialog_brain.jdb, recompile via MCP, see the change next turn) cut iteration time on prompt engineering down to seconds. Doing this from a compiled GDScript or C++ would have been miserable.
What's next?
Next on the list: persistence across sessions, NPC-to-NPC rumour propagation (right now rumours only spread through the player), and a fourth story act for the keep itself. Combat is on the wish-list but feels like a separate project.
The whole thing lives on the godot_spinoff branch of the jdBasic repo, with a step-by-step setup guide in the demo's README. If you have a 12 GB VRAM card and an afternoon, you can have your own four NPCs gossiping about you by dinner.
Resources
- Demo README (install + run guide): github.com/AtomiJD/jdBasic - godot/rpg-demo/README.md
- jdBasic main repo: github.com/AtomiJD/jdBasic (branch
godot_spinofffor this demo) - jdBasic Lesson 01 on YouTube: Getting started with jdBasic